1.2 Data, Sampling, and Variation in Data and Sampling
Gögn geta komið úr þýði eða úrtaki. Lágstafir eins og x eða y eru almennt notaðir til að tákna gagnagildi. Flestum gögnum má skipta í eftirfarandi flokka:
- Eigindleg
- Megindleg
Eigindleg gögn eru afrakstur þess að flokka eða lýsa eiginleikum þýðis. Eigindleg gögn eru einnig oft kölluð flokkuð gögn. Hárlitur, blóðflokkur, þjóðerni, bíllinn sem manneskja keyrir og gatan sem hún býr við eru dæmi um eigindleg gögn. Eigindlegum gögnum er almennt lýst með orðum eða bókstöfum. Til dæmis gæti hárlitur verið svartur, dökkbrúnn, ljósbrúnn, ljóst, grátt eða rautt. Blóðflokkur gæti verið AB+, O– eða B+. Rannsakendur kjósa oft að nota megindleg gögn fram yfir eigindleg gögn vegna þess að þau henta betur til stærðfræðilegrar greiningar. Til dæmis er ekki merkingarbært að reikna meðalhárlit eða meðalblóðflokk.
Megindleg gögn eru alltaf tölur. Megindleg gögn eru afrakstur þess að telja eða mæla eiginleika þýðis. Peningaupphæð, púls, þyngd, fjöldi fólks sem býr í bænum þínum og fjöldi nemenda sem eru í tölfræðiáfanga eru dæmi um megindleg gögn. Megindleg gögn geta verið annaðhvort strjál eða samfelld.
Öll gögn sem eru afrakstur talningar kallast strjál megindleg gögn. Þessi gögn taka aðeins ákveðin tölugildi. Ef þú telur fjölda símtala sem þú færð hvern dag vikunnar gætirðu fengið gildi eins og núll, eitt, tvö eða þrjú.
Gögn sem samanstanda ekki aðeins af talningartölum, heldur geta innihaldið brot, tugabrot eða óræðar tölur, kallast samfelld megindleg gögn. Samfelld gögn eru oft afrakstur mælinga eins og lengdar, þyngdar eða tíma. Listi yfir lengd í mínútum fyrir öll símtöl sem þú hringir í viku, með tölum eins og 2,4, 7,5 eða 11,0, væri samfelld megindleg gögn.
Dæmi 1.5
Gögnin eru fjöldi bóka sem nemendur bera í bakpokum sínum. Þú tekur úrtak af fimm nemendum. Tveir nemendur bera þrjár bækur, einn nemandi ber fjórar bækur, einn nemandi ber tvær bækur og einn nemandi ber eina bók. Fjöldi bóka, 3, 4, 2 og 1, eru strjálu megindlegu gögnin.
Dæmi 1.6
Gögnin eru þyngd bakpoka með bókum í. Þú tekur úrtak af sömu fimm nemendunum. Þyngdir bakpoka þeirra, í pundum, eru 6,2, 7, 6,8, 9,1 og 4,3. Taktu eftir að bakpokar sem bera þrjár bækur geta haft mismunandi þyngd. Þyngdir eru samfelld megindleg gögn.
Dæmi 1.7
Þú ferð í stórmarkaðinn og kaupir þrjár dósir af súpu (19 únsur af tómatsúpu, 14,1 únsur af linsubaunasúpu og 19 únsur af ítalskri brúðkaupssúpu), tvo pakka af hnetum (valhnetur og jarðhnetur), fjórar mismunandi tegundir af grænmeti (brokkólí, blómkál, spínat og gulrætur) og tvo eftirrétti (16 únsur af pistasíuís og 32 únsur af súkkulaðibitakökum).
Nefndu gagnasöfn sem eru megindleg strjál, megindleg samfelld og eigindleg.
Reyndu að bera kennsl á fleiri gagnasöfn í þessu dæmi.
Lausn
Möguleg lausn
Dæmi 1.8
Gögnin eru litir á bakpokum. Aftur tekur þú úrtak af sömu fimm nemendunum. Einn nemandi er með rauðan bakpoka, tveir nemendur eru með svarta bakpoka, einn nemandi er með grænan bakpoka og einn nemandi er með gráan bakpoka. Litirnir rauður, svartur, svartur, grænn og grár eru eigindleg gögn.
Dæmi 1.9
Vinnið saman að því að ákvarða rétta gagnategund: megindleg eða eigindleg. Tilgreinið hvort megindleg gögn séu samfelld eða strjál. Vísbending: Gögn sem eru strjál byrja oft á orðunum fjöldi.
- fjöldi skópöra sem þú átt
- tegund bíls sem þú keyrir
- fjarlægðin frá heimili þínu að næstu matvöruverslun
- fjöldi áfanga sem þú tekur á skólaári
- tegund reiknivélar sem þú notar
- þyngd súmóglímumanna
- fjöldi réttra svara á prófi
- Greindarvísitala (Þetta gæti valdið einhverjum umræðum.)
Lausn
Liðir a, d og g eru megindleg strjál; liðir c, f og h eru megindleg samfelld; liðir b og e eru eigindleg eða flokkuð gögn.
Dæmi 1.10
Tölfræðiprófessor safnar upplýsingum um flokkun nemenda sinna sem nýnema á fyrsta, öðru, þriðja eða fjórða ári. Gögnin sem hún safnar eru tekin saman í skífuritinu á mynd 1.3. Hvers konar gögn sýnir þetta rit?
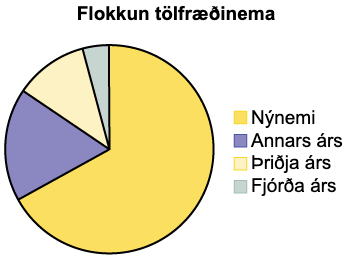
Lausn
Þetta skífurit sýnir námsár nemenda, sem eru eigindleg eða flokkuð gögn.
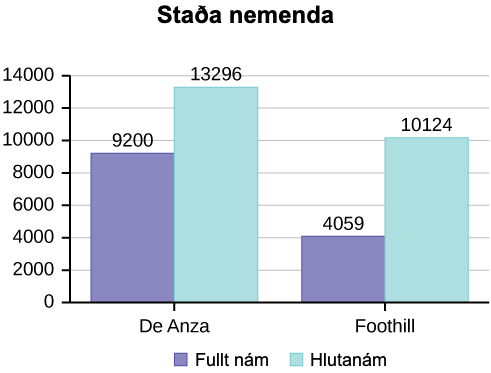
Hér að neðan eru töflur sem bera saman fjölda nemenda í hlutanámi og fullu námi við De Anza College og Foothill College sem voru skráðir á vorönn 2010. Töflurnar sýna fjölda, prósentur og hlutfallstíðni. Til dæmis, til að reikna út prósentu nemenda í hlutanámi við De Anza College, deilirðu 9.200/22.496 og færð 0,4089. Námundaðu að næsta þúsundasta hluta, það er að þriðja aukastaf, og margfaldaðu síðan með 100 til að fá prósentuna, 40,9 prósent.
Þannig auðvelda prósentudálkarnir samanburð á sömu flokkum milli háskólanna. Það er oft gagnlegt að sýna prósentur ásamt fjöldatölum, en það er sérstaklega mikilvægt þegar borin eru saman gagnasöfn með ólíkan heildarfjölda, eins og heildarinnritun í háskólunum tveimur í þessu dæmi. Taktu eftir hversu miklu hærra hlutfall nemenda í hlutanámi er við Foothill College en við De Anza College.
| De Anza College | Foothill College | |||||
|---|---|---|---|---|---|---|
| Fjöldi | Prósenta | Fjöldi | Prósenta | |||
| Fullt nám | 9.200 | 40,90% | Fullt nám | 4.059 | 28,60% | |
| Hlutanám | 13.296 | 59,10% | Hlutanám | 10.124 | 71,40% | |
| Samtals | 22.496 | 100% | Samtals | 14.183 | 100% |
Töflur eru góð leið til að skipuleggja og birta gögn. En myndrit geta verið enn gagnlegri til að skilja gögnin.
Tvö myndrit sem notuð eru til að birta eigindleg gögn eru skífurit og stöplarit.
Í skífuriti eru gagnaflokkar sýndir með geirum í hring sem tákna hlutfall einstaklinga eða atriða í hverjum flokki. Við notum skífurit þegar við viljum sýna hluta af heild.
Í stöplariti táknar lengd stöplans fyrir hvern flokk fjölda eða prósentu einstaklinga í hverjum flokki. Stöplar geta verið lóðréttir eða láréttir. Við notum stöplarit þegar við viljum bera saman flokka eða sýna breytingar yfir tíma.
Pareto-rit samanstendur af stöplum sem eru raðaðir eftir stærð flokka (frá stærsta til minnsta).
Skoðaðu mynd 1.5 og mynd 1.6 og ákvarðaðu hvort þér finnist skífuritið eða stöplaritið sýna samanburðinn betur.
Það er góð hugmynd að skoða ýmis myndrit til að sjá hvaða framsetning er gagnlegust fyrir gögnin. Við gætum valið mismunandi myndrit eftir gögnunum og samhenginu. Valið fer einnig eftir því til hvers við ætlum að nota gögnin.

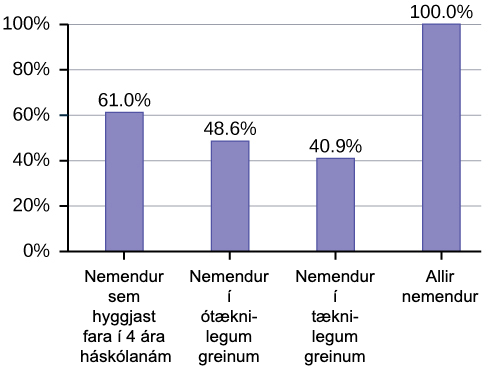
Stundum leggjast prósentur saman í meira en 100 prósent (eða minna en 100 prósent). Í myndritinu leggjast prósenturnar saman í meira en 100 prósent vegna þess að nemendur geta verið í fleiri en einum flokki. Stöplarit er viðeigandi til að bera saman hlutfallslega stærð flokkanna. Ekki er hægt að nota skífurit. Það væri heldur ekki hægt að nota það ef prósenturnar legðust saman í minna en 100 prósent.
| Einkenni/flokkur | Prósenta |
|---|---|
| Nemendur sem læra tæknigreinar | 40,9% |
| Nemendur sem læra aðrar greinar en tæknigreinar | 48,6% |
| Nemendur sem ætla að flytjast í fjögurra ára menntastofnun | 61,0% |
| SAMTALS | 150,5% |
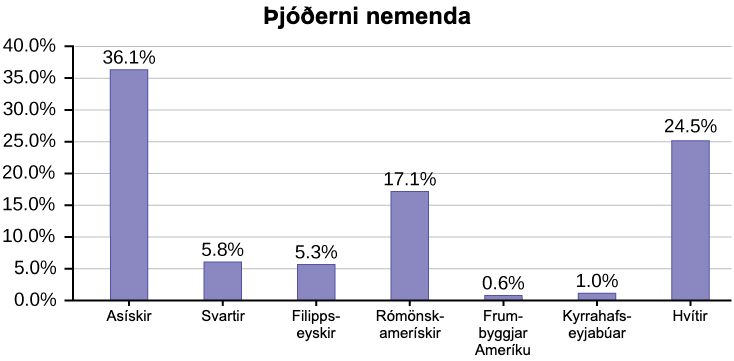
Taflan sýnir þjóðerni nemenda en í hana vantar flokkinn Annað/óþekkt. Þessi flokkur inniheldur fólk sem taldi sig ekki falla í neinn af þjóðernisflokkunum eða neitaði að svara. Taktu eftir að tíðnirnar leggjast ekki saman í heildarfjölda nemenda. Í þessari stöðu skaltu búa til stöplarit en ekki skífurit.
| Tíðni | Prósenta | |
|---|---|---|
| Asíubúar | 8.794 | 36,1% |
| Svartir | 1.412 | 5,8% |
| Filippseyingar | 1.298 | 5,3% |
| Rómönsk-amerískir | 4.180 | 17,1% |
| Frumbyggjar Ameríku | 146 | 0,6% |
| Kyrrahafseyjamenn | 236 | 1,0% |
| Hvítir | 5.978 | 24,5% |
| SAMTALS | 22.044 af 24.382 | 90,4% af 100% |
Eftirfarandi myndrit er það sama og fyrra myndrit en Annað/óþekkt prósentan (9,6 prósent) hefur verið tekin með. Annað/óþekkt flokkurinn er stór miðað við suma hina flokkana (frumbyggjar Ameríku, 0,6 prósent, Kyrrahafseyjamenn 1,0 prósent). Þetta er mikilvægt að vita þegar við hugsum um hvað gögnin eru að segja okkur.
Þetta tiltekna stöplarit á mynd 1.9 getur verið erfitt að skilja sjónrænt. Myndritið á mynd 1.10 er Pareto-rit. Pareto-ritið hefur stöpla raðað frá stærsta til minnsta og er auðveldara að lesa og túlka.
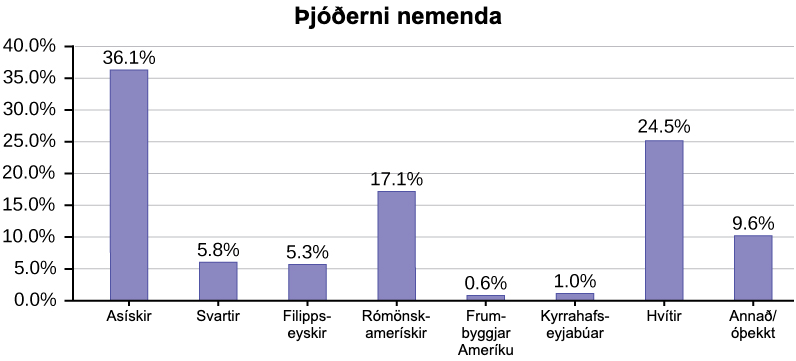

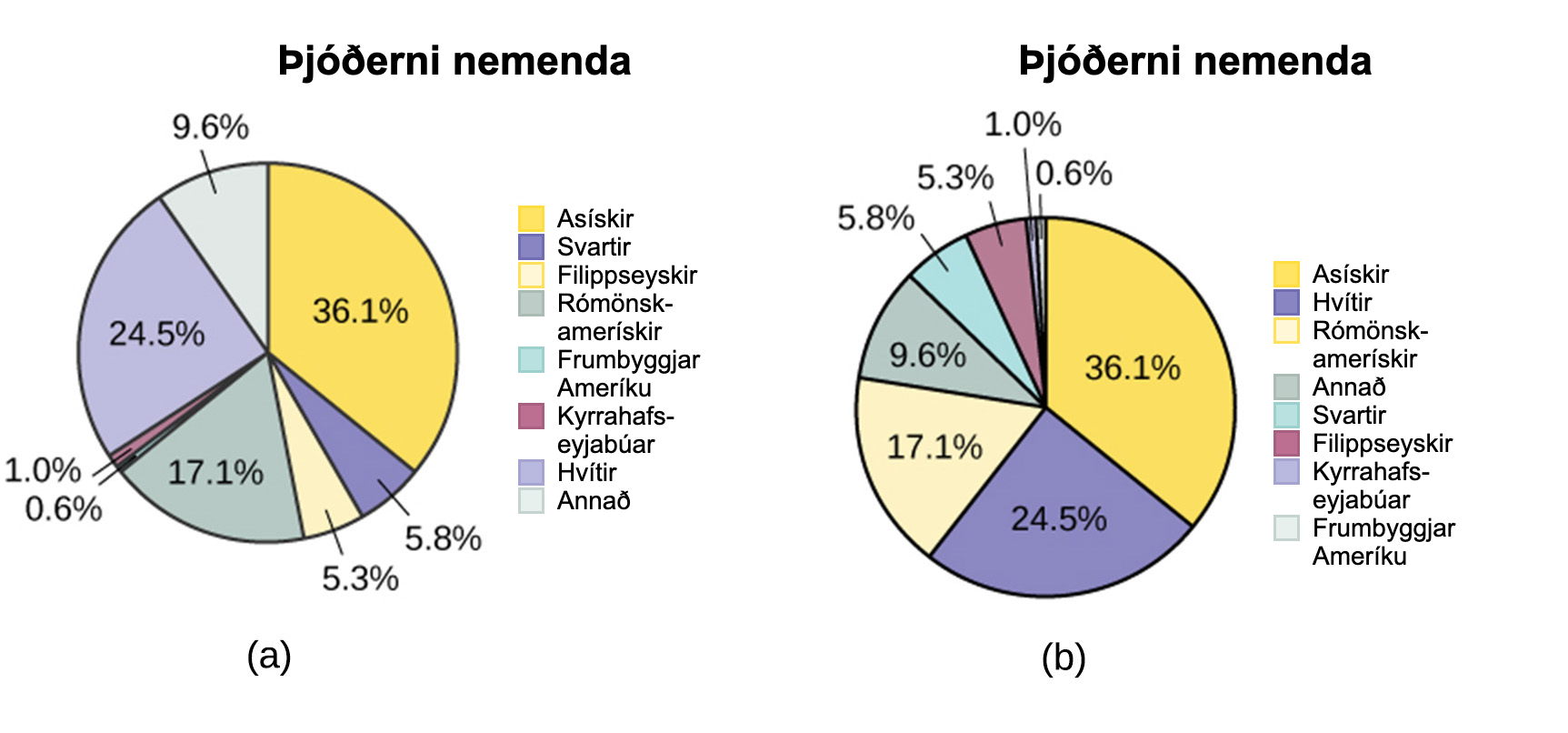
Eftirfarandi skífurit hafa Annað/óþekkt flokkinn með þar sem prósenturnar verða að leggjast saman í 100 prósent. Myndritið á mynd 1.11 b er skipulagt eftir stærð hvers geira, sem gerir það að sjónrænt upplýsandi myndriti en óraðaða, stafrófsraðaða myndritið á mynd 1.11 a.
Hér að neðan er krosstafla, sem einnig er kölluð krossflokkunartafla, og sýnir uppáhaldsíþróttir 50 fullorðinna: 20 kvenna og 30 karla.
| Amerískur fótbolti | Körfubolti | Tennis | Samtals | |
|---|---|---|---|---|
| Karlar | 20 | 8 | 2 | 30 |
| Konur | 5 | 7 | 8 | 20 |
| Samtals | 25 | 15 | 10 | 50 |
Þetta er krossflokkunartafla vegna þess að hún sýnir upplýsingar um tvær flokkabreytur, í þessu tilfelli kyn og íþróttir. Gögn af þessari gerð (gögn um tvær breytur) eru kölluð tvíbreytugögn. Vegna þess að gögnin tákna fjölda, eða talningu, á valkostum, er þetta krosstíðnitafla. Færslurnar í samtals-röðinni og samtals-dálkinum tákna jaðartíðnir eða jaðardreifingar. Athugið—Hugtakið jaðardreifingar dregur nafn sitt af því að dreifingarnar finnast á jöðrum tíðnidreifingartaflna. Jaðardreifingar geta verið gefnar upp sem brot eða tugabrot: Til dæmis gæti heildarfjöldi karla verið gefinn upp sem 0,6 eða 3/5 þar sem 30 / 50 = 0,6 = 3 / 5. Jaðardreifingar krefjast tvíbreytugagna og einblína aðeins á eina af breytunum sem táknaðar eru í töflunni. Með öðrum orðum, ástæðan fyrir því að 20 er jaðartíðni í þessari krossflokkunartöflu er sú að hún táknar jaðarinn eða þann hluta heildarþýðisins sem eru konur (20/50). Ástæðan fyrir því að 25 er jaðartíðni er sú að hún táknar þann hluta þeirra sem voru í úrtakinu sem kjósa amerískan fótbolta (25/50). Athugið: Gildin sem mynda meginhluta töflunnar (t.d. 20, 8, 2) eru kölluð sameiginlegar tíðnir.
Munurinn á jaðardreifingu og skilyrtri dreifingu er sá að áherslan er aðeins á tiltekið undirþýði (ekki allt þýðið). Til dæmis, í töflunni, ef við einblíndum aðeins á undirþýði kvenna sem kjósa amerískan fótbolta, þá gætum við reiknað skilyrtar dreifingar eins og sýnt er í krossflokkunartöflunni hér að neðan.
| Amerískur fótbolti | Körfubolti | Tennis | Samtals | |
|---|---|---|---|---|
| Karlar | 20 | 8 | 2 | 30 |
| Konur | 5 | 7 | 8 | 20 |
| Samtals | 25 | 15 | 10 | 50 |
Til að finna undirhóp þeirra sem kjósa amerískan fótbolta og eru konur, lestu gildið á skurðpunkti kvennaröðvarinnar og ameríska fótboltadálksins sem er 5. Deildu þessu síðan með heildarfjölda þeirra sem kjósa amerískan fótbolta, sem er 25. Þannig er undirhópur þeirra sem kjósa amerískan fótbolta og eru konur 5/25 sem er 0,2.
Sömuleiðis, til að finna þann undirhóp kvenna sem kýs amerískan fótbolta, skal nota gildið 5 sem er fjöldi kvenna sem kýs amerískan fótbolta. Deilið því síðan með heildarfjölda kvenna sem er 20. Þannig er undirhópur kvenna sem kýs amerískan fótbolta 5/20 sem er 0,25.
Eftir að hafa ákveðið hvaða myndrit sýnir gögnin þín best gætirðu þurft að kynna tölfræðigögnin fyrir bekk eða öðrum hópi í munnlegri skýrslu eða margmiðlunarkynningu. Í munnlegri kynningu þarftu að geta útskýrt nákvæmlega hvernig þú safnaðir eða reiknaðir gögnin og hvers vegna þú valdir þá flokka, kvarða og gerðir myndrita sem þú sýnir. Þótt þú hafir ef til vill gert mörg myndrit af gögnunum skaltu aðeins nota þau sem sýna raunverulega yfirlýstan tilgang tölfræðirannsóknarinnar. Við undirbúning kynningarinnar skaltu ganga úr skugga um að allir litir, texti og kvarðar séu sýnilegir öllum áheyrendum. Að lokum skaltu gefa áheyrendum tíma til að spyrja spurninga og geta svarað þeim.
Dæmi 1.11
Gerum ráð fyrir að námsráðgjafarnir við De Anza og Foothill þurfi að halda munnlega kynningu á nemendagögnunum sem sýnd eru á myndum 1.5 og 1.6. Í hvaða samhengi ættu þeir að velja að sýna skífuritið? Hvenær gætu þeir valið stöplaritið? Útskýrðu fyrir hvort myndrit um sig hvaða eiginleika þeir ættu að benda á og hvaða hugsanlegu vandamál við framsetningu gætu verið til staðar.
Lausn
Námsráðgjafarnir ættu að nota skífuritið ef óskað er eftir upplýsingum um hlutfall innritana í hvorum skóla. Þeir ættu að nota stöplaritið ef mikilvægt er að koma á framfæri nákvæmum fjölda nemenda og hlutfallslegri stærð hvers flokks í hvorum skóla. Fyrir skífuritið ættu þeir að benda á hvaða litur táknar hlutanema og hver táknar fullt nám. Þeir ættu einnig að tryggja að tölur og litir séu sýnileg þegar þau eru birt. Fyrir stöplaritið ættu þeir að benda á kvarðann og heildarfjölda fyrir hvern flokk, og þeir ættu að tryggja að tölur, litir og kvarðamerkingar séu öll greinilega sýnileg.
Að safna upplýsingum um heilt þýði kostar oft of mikið eða er nánast ómögulegt. Þess í stað notum við úrtak úr þýðinu. Úrtak ætti að hafa sömu eiginleika og þýðið sem það er fulltrúi fyrir. Flestir tölfræðingar nota ýmsar aðferðir við slembiúrtöku í tilraun til að ná þessu markmiði. Þessi hluti mun lýsa nokkrum af algengustu aðferðunum. Það eru til nokkrar mismunandi aðferðir við slembiúrtöku. Í hverri tegund slembiúrtöku hefur hver einstaklingur í þýðinu upphaflega jafnar líkur á að vera valinn í úrtakið. Hver aðferð hefur kosti og galla. Auðveldasta aðferðin til að lýsa kallast einfalt slembiúrtak. Í einföldu slembiúrtaki hefur hvert úrtak sömu líkur á að vera valið. Með öðrum orðum hefur hvert úrtak af sömu stærð jafnar líkur á að vera valið. Til dæmis, gerum ráð fyrir að Lísa vilji mynda fjögurra manna námshóp (sig og þrjá aðra) úr stærðfræðiáfanganum sínum, sem hefur 31 nemanda fyrir utan Lísu. Til að velja einfalt slembiúrtak af stærðinni þrír úr hinum nemendunum í bekknum gæti Lísa sett öll 31 nöfnin í hatt, hrist hattinn, lokað augunum og dregið þrjú nöfn. Tæknilegri leið er fyrir Lísu að skrá fyrst eftirnöfn nemendanna í bekknum ásamt tveggja stafa tölu, eins og í töflu 1.7.
| Auðkenni | Nafn | Auðkenni | Nafn | Auðkenni | Nafn |
|---|---|---|---|---|---|
| 00 | Anselmo | 11 | King | 22 | Roquero |
| 01 | Bautista | 12 | Legeny | 23 | Roth |
| 02 | Bayani | 13 | Lisa | 24 | Rowell |
| 03 | Cheng | 14 | Lundquist | 25 | Salangsang |
| 04 | Cuarismo | 15 | Macierz | 26 | Slade |
| 05 | Cuningham | 16 | Motogawa | 27 | Stratcher |
| 06 | Fontecha | 17 | Okimoto | 28 | Tallai |
| 07 | Hong | 18 | Patel | 29 | Tran |
| 08 | Hoobler | 19 | Price | 30 | Wai |
| 09 | Jiao | 20 | Quizon | 31 | Wood |
| 10 | Khan | 21 | Reyes |
Lísa getur notað töflu með slembitölum (sem finna má í mörgum tölfræðibókum og stærðfræðihandbókum), reiknivél eða tölvu til að búa til slembitölur. Algengustu slembitölugjafarnir eru fimm stafa tölur þar sem hver stafur er ein tala frá 0 til 9. Fyrir þetta dæmi skulum við gera ráð fyrir að Lísa velji að búa til slembitölur með reiknivél. Tölurnar sem verða til eru eftirfarandi:
0,94360, 0,99832, 0,14669, 0,51470, 0,40581, 0,73381, 0,04399.
Lísa les tveggja stafa hópa þar til hún hefur valið þrjá bekkjarfélaga (Það er, hún les 0,94360 sem hópana 94, 43, 36, 60). Hver slembitala getur aðeins gefið af sér einn bekkjarfélaga. Ef hún þyrfti þess gæti Lísa búið til fleiri slembitölur.
Taflan hér að neðan sýnir hvernig Lísa les tveggja stafa tölur úr hverri slembitölu. Hver tveggja stafa tala í töflunni myndi tákna hvern nemanda á listanum hér að ofan í töflu 1.7.
| Slembitala | Tölur lesnar af Lísu | |||
|---|---|---|---|---|
| 0,94360 | 94 | 43 | 36 | 60 |
| 0,99832 | 99 | 98 | 83 | 32 |
| 0,14669 | 14 | 46 | 66 | 69 |
| 0,51470 | 51 | 14 | 47 | 70 |
| 0,40581 | 40 | 05 | 58 | 81 |
| 0,73381 | 73 | 33 | 38 | 81 |
| 0,04399 | 04 | 39 | 39 | 99 |
Slembitölurnar 0,94360 og 0,99832 innihalda ekki viðeigandi tveggja stafa tölur. Hins vegar inniheldur þriðja slembitalan, 0,14669, 14 (fjórða slembitalan inniheldur einnig 14), fimmta slembitalan inniheldur 05 og sjöunda slembitalan inniheldur 04. Tveggja stafa talan 14 samsvarar Lundquist, 05 samsvarar Cuningham og 04 samsvarar Cuarismo. Fyrir utan hana sjálfa mun hópur Lísu samanstanda af Lundquist, Cuningham og Cuarismo.
Auk einfaldrar slembiúrtöku eru til aðrar tegundir úrtöku sem fela í sér líkindaferli til að fá úrtakið. Aðrar þekktar slembiúrtaksaðferðir eru lagskipt slembiúrtak, klasaúrtak og kerfisbundið úrtak.
Til að velja lagskipt slembiúrtak er þýðinu skipt í hópa sem kallast lög og síðan er úrtakið valið með því að velja gildi úr hverju lagi þar til æskilegri úrtaksstærð er náð. Til dæmis gætirðu lagskipt (flokkað) nemendaþýði í framhaldsskóla eftir árgöngum (fyrsta, annars, þriðja og fjórða árs nemar) og síðan valið hlutfallslegt einfalt slembiúrtak úr hverju lagi (hverjum árgangi) til að fá lagskipt slembiúrtak. Til að velja einfalt slembiúrtak úr hverjum árgangi skal tölusetja hvern nemanda á fyrsta ári, tölusetja hvern nemanda á öðru ári og gera það sama fyrir eftirstandandi árganga. Notaðu síðan einfalda slembiúrtöku til að velja hlutfallslegan fjölda nemenda af fyrsta ári og gerðu það sama fyrir hvern af eftirstandandi árgöngum. Þær tölur sem valdar eru úr fyrsta ári, valdar úr öðru ári og svo framvegis tákna þá nemendur sem mynda lagskipta úrtakið.
Til að velja klasaúrtak er þýðinu skipt í klasa (hópa) og síðan eru nokkrir klasar valdir af handahófi. Allir meðlimir úr þessum klösum eru í klasaúrtakinu. Til dæmis, ef þú velur af handahófi fjóra umsjónarbekki úr nemendaþýðinu þínu, mynda þessir fjórir bekkir klasaúrtakið. Hver bekkur er klasi. Númeraðu hvern klasa og veldu síðan fjórar mismunandi tölur með einfaldri slembiúrtöku. Allir nemendur í bekkjunum fjórum með þessar tölur eru klasaúrtakið. Þannig að, ólíkt lagskiptu úrtaki, gæti klasaúrtak ekki innihaldið jafnmarga nemendur valda af handahófi úr hverjum bekk.
Til að velja kerfisbundið úrtak skal setja reglu og fylgja henni. Algengasta leiðin til að velja kerfisbundið úrtak er að skrá meðlimi þýðisins og velja n-tu færslu frá handahófskenndum upphafspunkti. Til dæmis, gerum ráð fyrir að þú hafir 100.000 einstaklinga í þýðinu þínu og þú viljir velja úrtak af stærðinni 1.000. Notaðu slembitölugjafa til að velja upphafspunktinn þinn. Nú er 100.000/1.000 = 100, þannig að til að tryggja dreifingu yfir allan listann skal velja 100. hverja færslu á listanum. Þegar þú nærð enda listans skaltu halda talningunni áfram frá byrjun þar til þú hefur valið allt úrtakið.
Ein tegund úrtöku sem er ekki slembiháð er hentugleikaúrtak. Hentugleikaúrtak felur í sér að nota niðurstöður sem eru auðveldlega aðgengilegar. Til dæmis framkvæmir hugbúnaðarverslun markaðsrannsókn með því að taka viðtöl við hugsanlega viðskiptavini sem eru af tilviljun í versluninni að skoða fáanlegan hugbúnað. Niðurstöður hentugleikaúrtaks geta verið mjög góðar í sumum tilfellum en mjög bjagaðar, það er þær geta hyglað ákveðnum niðurstöðum, í öðrum.
Söfnun úrtaksgagna ætti að fara fram af mikilli varkárni. Kærulaus gagnasöfnun getur haft skelfilegar afleiðingar. Kannanir sem sendar eru á heimili og síðan endursendar geta verið mjög bjagaðar. Þær gætu hyglað ákveðnum hópi. Betra er að sá sem framkvæmir könnunina velji svarendur í úrtakið.
Þegar gögn eru greind er mikilvægt að vera meðvitaður um úrtaksvillur og villur sem tengjast ekki úrtöku. Sjálft úrtaksferlið veldur úrtaksvillum. Til dæmis gæti úrtakið ekki verið nógu stórt. Þættir sem tengjast ekki úrtaksferlinu valda öðrum skekkjum. Gallað talningartæki getur valdið slíkri skekkju.
Í raun mun úrtak aldrei vera nákvæmlega dæmigert fyrir þýðið, þannig að alltaf verður einhver úrtaksvilla. Að jafnaði gildir að því stærra sem úrtakið er, því minni er úrtaksvillan.
Í tölfræði verður úrtaksbjagi til þegar úrtak er tekið úr þýði og sumir meðlimir þýðisins eru ólíklegri til að vera valdir en aðrir. Munum að hver meðlimur þýðisins ætti að hafa jafnar líkur á að vera valinn. Þegar úrtaksbjagi á sér stað er hægt að draga rangar ályktanir um þýðið sem verið er að rannsaka. Til dæmis, ef könnun meðal allra nemenda er aðeins framkvæmd á hádegismatartíma er hún bjöguð. Þetta er vegna þess að nemendur sem ekki hafa hádegismatartíma myndu ekki vera með.
Við þurfum að meta tölfræðirannsóknir sem við lesum um á gagnrýninn hátt og greina þær áður en við samþykkjum niðurstöður þeirra. Algeng vandamál sem þarf að vera meðvitaður um eru meðal annars eftirfarandi:
- Vandamál með úrtök: Úrtak verður að vera dæmigert fyrir þýðið. Úrtak sem er ekki dæmigert fyrir þýðið er bjagað. Bjöguð úrtök sem eru ekki dæmigerð fyrir þýðið gefa niðurstöður sem eru ónákvæmar og óáreiðanlegar. Einnig verður að huga að áreiðanleika í tölfræðilegum mælingum þegar gögn eru greind. Áreiðanleiki vísar til samræmis mælingar. Mæling er áreiðanleg þegar sömu niðurstöður fást við sömu aðstæður.
- Sjálfvalin úrtök: Svör eingöngu frá fólki sem velur að svara, eins og í netkönnunum, eru oft óáreiðanleg.
- Vandamál með úrtaksstærð: Úrtök sem eru of lítil geta verið óáreiðanleg. Stærri úrtök eru betri, ef mögulegt er. Í sumum aðstæðum er óhjákvæmilegt að hafa lítil úrtök og samt er hægt að nota þau til að draga ályktanir. Dæmi um þetta eru árekstrarprófanir á bílum eða læknisfræðilegar prófanir á sjaldgæfum sjúkdómum.
- Óeðlileg áhrif: að safna gögnum eða spyrja spurninga á þann hátt sem hefur áhrif á svarið.
- Svarleysi eða neitun þátttakanda um að taka þátt: Söfnuð svör gætu ekki lengur verið dæmigerð fyrir þýðið. Oft svarar fólk með sterkar jákvæðar eða neikvæðar skoðanir könnunum, sem getur haft áhrif á niðurstöðurnar.
- Orsakasamhengi: Samband milli tveggja breyta þýðir ekki að önnur orsaki hina. Þær gætu verið tengdar (fylgni) vegna sambands þeirra í gegnum aðra breytu.
- Hagsmunatengdar eða eiginfjármagnaðar rannsóknir: Rannsókn er framkvæmd af einstaklingi eða stofnun til að styðja eigin fullyrðingu. Er rannsóknin hlutlaus? Lestu rannsóknina vandlega til að meta vinnuna. Ekki gera sjálfkrafa ráð fyrir að rannsóknin sé góð eða slæm. Metið hana á eigin forsendum og út frá vinnunni sem var unnin.
- Villandi notkun gagna: Þetta geta verið rangt framsett myndrit, ófullkomin gögn eða skortur á samhengi.
Dæmi 1.12
Rannsókn er gerð til að ákvarða meðalskólagjöld sem nemendur í einkareknum framhaldsskólum greiða á önn. Hver nemandi í eftirfarandi úrtökum er spurður hversu mikið hann eða hún greiddi í skólagjöld fyrir haustönnina. Hver er tegund úrtaks í hverju tilviki?
- Úrtak 100 framhaldsskólanema er tekið með því að flokka nöfn nemendanna eftir námsári (fyrsta, annað, þriðja eða fjórða ár) og velja síðan 25 nemendur úr hverjum hópi.
- Slembitölugjafi er notaður til að velja nemanda úr stafrófsröðuðum lista yfir alla framhaldsskólanema á haustönn. Frá þeim nemanda er fimmtugasti hver nemandi valinn þar til 75 nemendur eru komnir í úrtakið.
- Algjörlega slembin aðferð er notuð til að velja 75 nemendur. Hver framhaldsskólanemi á haustönn hefur sömu líkur á að vera valinn á hvaða stigi úrtaksferlisins sem er.
- Fyrsta, annað, þriðja og fjórða námsár eru númeruð eitt, tvö, þrjú og fjögur, í sömu röð. Slembitölugjafi er notaður til að velja tvö af þessum árum. Allir nemendur á þessum tveimur árum eru í úrtakinu.
- Aðstoðarmaður í stjórnsýslu er beðinn um að standa fyrir framan bókasafnið einn miðvikudag og spyrja fyrstu 100 grunnnemana sem hann hittir hvað þeir greiddu í skólagjöld á haustönn. Þessir 100 nemendur eru úrtakið.
Lausn
a. lagskipt, b. kerfisbundið, c. einfalt slembiúrtak, d. klasaúrtak, e. hentugleikaúrtak
Dæmi 1.13
Ákvarðið hvaða tegund úrtaks var notuð (einfalt slembiúrtak, lagskipt, kerfisbundið, klasa- eða hentugleikaúrtak).
- Knattspyrnuþjálfari velur sex leikmenn úr hópi drengja á aldrinum átta til tíu ára, sjö leikmenn úr hópi drengja á aldrinum 11 til 12 ára, og þrjá leikmenn úr hópi drengja á aldrinum 13 til 14 ára til að mynda áhugamannalið í fótbolta.
- Skoðanakannandi tekur viðtöl við allt starfsfólk mannauðsdeilda í fimm mismunandi tæknifyrirtækjum.
- Menntarannsakandi í framhaldsskóla tekur viðtöl við 50 kvenkyns framhaldsskólakennara og 50 karlkyns framhaldsskólakennara.
- Læknisfræðilegur rannsakandi tekur viðtal við þriðja hvern krabbameinssjúkling af lista yfir krabbameinssjúklinga á staðbundnu sjúkrahúsi.
- Námsráðgjafi í framhaldsskóla notar tölvu til að búa til 50 slembitölur og velur síðan nemendur sem bera nöfn sem svara til talnanna.
- Nemandi tekur viðtöl við bekkjarfélaga í algebrutíma sínum til að ákvarða hversu margar gallabuxur nemandi á að meðaltali.
Lausn
a. lagskipt b. klasa c. lagskipt d. kerfisbundið e. einfalt slembiúrtak f. hentugleika
Ef við myndum skoða tvö úrtök sem eru dæmigerð fyrir sama þýði, jafnvel þótt við notuðum slembiúrtaksaðferðir fyrir úrtökin, væru þau ekki nákvæmlega eins. Rétt eins og það er breytileiki í gögnum, er breytileiki í úrtökum. Eftir því sem þú venst úrtökum mun breytileikinn byrja að virðast eðlilegur.
Dæmi 1.14
Gerum ráð fyrir að ABC háskóli hafi 10.000 nemendur á þriðja og fjórða ári (á þriðja og fjórða ári) (þýðið). Við höfum áhuga á meðalupphæðinni sem fjórða árs nemandi eyðir í bækur á haustönn. Að spyrja alla 10.000 nemendur á þriðja og fjórða ári er nánast ómögulegt verkefni.
Gerum ráð fyrir að við tökum tvö mismunandi úrtök.
Fyrst notum við hentugleikaúrtak og könnum tíu fjórða árs nemendur úr lífrænni efnafræði á fyrstu önn. Margir þessara nemenda eru að taka stærðfræðigreiningu á fyrstu önn til viðbótar við lífræna efnafræði. Upphæðin sem þeir eyða í bækur er eftirfarandi:
$128, $87, $173, $116, $130, $204, $147, $189, $93, $153.
Seinna úrtakið er tekið með því að nota lista yfir fjórða árs nema sem taka íþróttanámskeið og velja fimmta hvern fjórða árs nema á listanum, samtals tíu fjórða árs nema. Þeir eyða eftirfarandi:
$50, $40, $36, $15, $50, $100, $40, $53, $22, $22.
Það er ólíklegt að nokkur nemandi sé í báðum úrtökum.
a. Telur þú að annað hvort þessara úrtaka sé dæmigert fyrir (eða einkennandi fyrir) allt þýðið, 10.000 nemendur á þriðja og fjórða ári?
b. Þar sem þessi úrtök eru ekki dæmigerð fyrir allt þýðið, er þá skynsamlegt að nota niðurstöðurnar til að lýsa öllu þýðinu?
Gerum nú ráð fyrir að við tökum þriðja úrtakið. Við veljum tíu mismunandi nemendur í hlutanámi úr námsbrautunum efnafræði, stærðfræði, ensku, sálfræði, félagsfræði, sagnfræði, hjúkrunarfræði, íþróttafræði, listum og þroskafræði. Við gerum ráð fyrir að þetta séu einu námsbrautirnar sem nemendur í hlutanámi við ABC-háskóla eru skráðir í og að jafn margir nemendur í hlutanámi séu skráðir á hverja námsbraut. Hver nemandi er valinn með einföldu slembiúrtaki. Með því að nota reiknivél eru slembitölur búnar til og nemandi af tiltekinni námsbraut er valinn ef hann eða hún hefur samsvarandi tölu. Nemendurnir eyða eftirfarandi upphæðum:
$180, $50, $150, $85, $260, $75, $180, $200, $200, $150.
c. Er úrtakið bjagað?
Nemendur spyrja oft hvort það sé nógu gott að taka úrtak í stað þess að kanna allt þýðið. Ef könnunin er vel gerð er svarið já.
Lausn
a. Nei. Fyrra úrtakið samanstendur líklega af nemendum í raungreinum. Auk efnafræðiáfangans eru sumir þeirra einnig í stærðfræðigreiningu á fyrstu önn. Bækur fyrir þessa áfanga eru oft dýrar. Flestir þessara nemenda eru líklega að borga meira fyrir bækurnar sínar en meðalnemandi. Seinna úrtakið er hópur nemenda á fjórða ári sem eru líklega að taka áfanga sér til heilsubótar og ánægju. Upphæðin sem þeir eyða í bækur er líklega mun lægri en hjá meðalnemanda. Bæði úrtökin eru bjöguð. Einnig, í báðum tilvikum, hafa ekki allir nemendur möguleika á að lenda í öðru hvoru úrtakinu.
b. Nei. Fyrir þessi úrtök hafði hver einstaklingur í þýðinu ekki jafnar líkur á að vera valinn.
c. Úrtakið er óbjagað, en mælt væri með stærra úrtaki til að auka líkurnar á að úrtakið sé sem næst því að vera dæmigert fyrir þýðið. Hins vegar, ef notuð er bjöguð úrtaksaðferð, er jafnvel stórt úrtak í hættu á að vera ekki dæmigert fyrir þýðið.
Breytileiki er til staðar í öllum gagnasöfnum. Til dæmis geta 16-únsu dósir af drykk innihaldið meira eða minna en 16 únsur af vökva. Í einni rannsókn voru átta 16 únsu dósir mældar og gáfu eftirfarandi magn (í únsum) af drykk:
15,8, 16,1, 15,2, 14,8, 15,8, 15,9, 16,0, 15,5.
Mælingar á magni drykkjar í 16-únsu dós geta verið breytilegar vegna þess að mismunandi fólk framkvæmir mælingarnar eða vegna þess að nákvæmlega 16 únsur af vökva voru ekki settar í dósirnar. Framleiðendur framkvæma reglulega prófanir til að ákvarða hvort magn drykkjar í 16-únsu dós falli innan æskilegra marka.
Vertu meðvitaður um að þegar þú safnar gögnum geta gögnin þín verið nokkuð frábrugðin gögnum sem einhver annar safnar í sama tilgangi. Þetta er fullkomlega eðlilegt. Hins vegar, ef tveir eða fleiri ykkar eru að safna sömu gögnum og fá mjög mismunandi niðurstöður, er kominn tími til að þú og hinir endurmetið gagnasöfnunaraðferðir ykkar og nákvæmni.
Áður var minnst á að tvö eða fleiri úrtök úr sama þýði, tekin af handahófi og með nánast sömu einkenni og þýðið, munu líklega vera frábrugðin hvort öðru. Gerum ráð fyrir að Doreen og Jung ákveði bæði að rannsaka meðalsvefntíma nemenda í framhaldsskólanum sínum á hverri nóttu. Doreen og Jung taka hvort um sig úrtak 500 nemenda. Doreen notar kerfisbundið úrtak og Jung notar klasaúrtak. Úrtak Doreen verður frábrugðið úrtaki Jung. Jafnvel þótt Doreen og Jung notuðu sömu úrtaksaðferð, væru úrtök þeirra að öllum líkindum frábrugðin. Hvorugt væri þó rangt.
Hugleiddu hvað stuðlar að því að gera úrtök Doreen og Jung mismunandi.
Ef Doreen og Jung tækju stærri úrtök, það er að segja, fjöldi gagnagilda væri aukinn, gætu niðurstöður úrtaka þeirra (meðalsvefntími nemanda) verið nær raunverulegu meðaltali þýðisins. En samt sem áður væru úrtök þeirra, að öllum líkindum, frábrugðin hvort öðru. Þetta kallast úrtaksbreytileiki. Með öðrum orðum vísar það til þess hversu mikið lýsistærð er breytileg frá einu úrtaki til annars innan þýðis. Því stærra sem úrtakið er, því minni verður breytileikinn á milli úrtaka. Þannig að stórt úrtak skilar betri og áreiðanlegri lýsistærð.
Stærð úrtaks, oft kölluð fjöldi athugana, er mikilvæg. Dæmin sem þú hefur séð í þessari bók hingað til hafa verið lítil. Úrtök með aðeins nokkur hundruð athugunum, eða jafnvel færri, duga í mörgum tilgangi. Í skoðanakönnunum eru úrtök með 1.200 til 1.500 athugunum talin nógu stór og nógu góð ef könnunin byggir á slembiúrtaki og er vel framkvæmd. Þú munt læra hvers vegna þegar þú rannsakar öryggisbil.
Vertu meðvitaður um að mörg stór úrtök eru bjöguð. Til dæmis eru netkannanir undantekningarlaust bjagaðar, vegna þess að fólk velur hvort það svarar eða ekki.